The last mile problem in Physical AI
We've all seen the demos by now. A robot folding laundry perfectly. Loading and unloading the dishwasher. Doing kung fu and backflips at the annual Chinese robotics show. Then you speak to someone who actually tried to deploy one of these robots and the story is very different.
To be clear - as mentioned in my last piece- we are not here to talk about humanoids. The demos are a useful proxy for how far the technology has come but the real prize sits in the industrial economy: the factories, warehouses, labs and logistics networks that make and move everything around us. That's where automation stops being a party trick and starts being the answer to labour shortages, reshoring and the productivity gap holding back the physical economy.

That gap is exactly what we want to unpack here.
The dirty secret of physical AI right now is that we are brilliant at training robots in simulation and still really bad at making them work reliably in the real world. Last time, I covered why robotics is having its foundation-model moment and where we are looking. This time we want to dig into why the sim-to-real gap persists and what it actually takes to close it.
To do that, it helps to understand how these robots are actually trained.
Why is the last mile still so hard?
We train robots in simulation for the same reason pilots train in flight simulators because it's cheaper, faster and safer than learning by crashing.
No manufacturer will hand over a live production line to a robot that's still learning and downtime is far too costly to learn by trial and error on the shop floor. The problem is that a simulator is a model of the world and all models are wrong in some ways.
With the World Cup on right now, here's a comparison - you spend years getting perfect at FIFA then someone hands you a real ball on a real pitch. And suddently you feel that the grass is uneven, there's wind, the ball doesn't bounce quite the way you expect. You're not starting from zero but you are also nowhere near your FIFA rating.
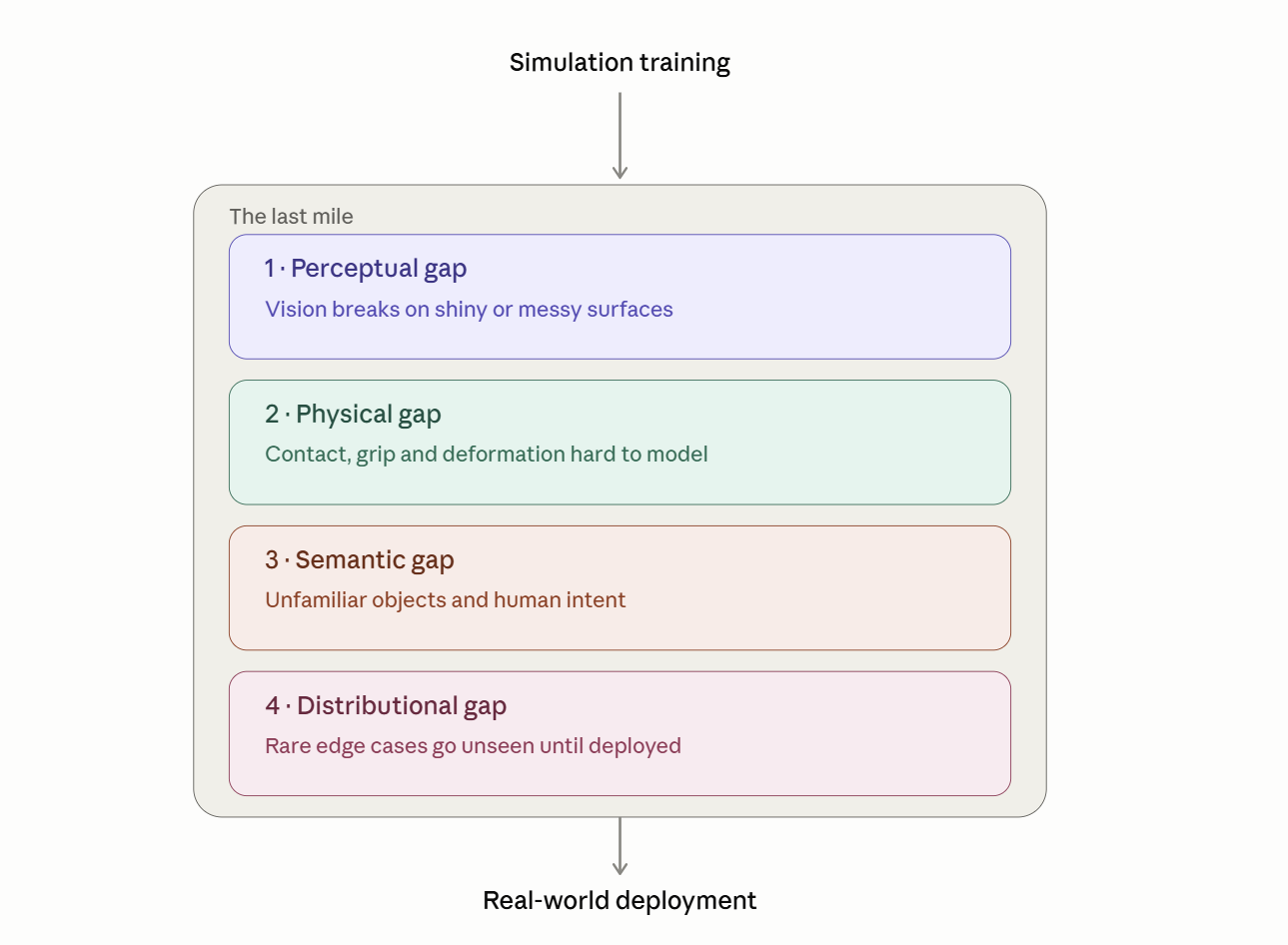
The gap has multiple layers: perception, physics, semantics and above all the distributional gap:
The Perceptual Gap (vision and sensing)
This is the most "famous" layer - the difference between how a simulator renders a scene and how a real camera perceives it.
Simulators use ray tracing or rasterisation to calculate how light behaves mathematically. This works beautifully for flat, matte surfaces. It breaks down on what engineers call "non-Lambertian" surfaces i.e. anything that’s shiny, transparent or reflective. Industrial environments are full of them i.e. polished metal parts, machined components, glass, shrink-wrapped pallets laying around. A robot might recognise a reflection off a stainless steel part as a completely different object or as a hole in the workbench.
It's not just the light, it's also the air. In sim, an object is either there or it isn't. In the real world, there is visual noise like dust from a grinding station, lens flares, steam from a wash-down line, all of which can make a robot lose track of a part it was just holding.
There's also an "uncanny valley" of textures. Simulators often use simplified surfaces so a robot trained on a perfect CAD-rendered workpiece gets confused by real-world scratches or residue. If there's a smudge of grease on the part, it genuinely gets confused by it.
The Physical Gap (dynamics and contact)
This is where most "superhuman" lab robots fail and closing it requires high-fidelity physics engines.
We can programme weight mathematically. The problem is contact. Simulators often treat objects as rigid bodies but in reality when a gripper touches a box there is micro-friction, slippage and vibration. Modelling the exact moment of impact is mathematically "stiff" and hard to compute. For humans, we don't think about any of this when a glass slips from our hand, our body just reacts whereas a robot has to compute it.
Then there's the deformables problem which is what roboticists call the "laundry problem", but on a factory floor it's cables, wire harnesses, flexible packaging etc. Simulating a rigid block is easy but simulating anything that bends or squishes requires Finite Element Analysis (FEA) - engineers break the object down into thousands of tiny polygons and the computer has to constantly calculate how each polygon pulls on every other polygon, every millisecond like an extremely complex 3D mesh. It's computationally expensive and rarely matches real-world "squishiness" perfectly. It's a big part of why cable routing and harness assembly, some of the most labour-intensive tasks in electronics manufacturing remain stubbornly manual.
And there's a hidden physical gap: latency. The time it takes for a command to travel from the "brain" to the motor is zero in sim but variable in reality - the robot is constantly lagging slightly behind itself which leads to shaky or unstable movements. On a production line running at takt time, that instability is the difference between a robot that pays back and one that gets switched off.
The Semantic Gap (meaning and intent)
Beyond seeing and touching, there's the understanding gap. This isn't about perceiving the world, it's about making sense of it.
A simulator might have 10 types of pallets. A real warehouse has damaged pallets, overloaded pallets and pallets with a hi-vis jacket slung over them. The robot struggles to identify the "pallet-ness" of an object it hasn't seen.
Human intent is the hardest part of the last mile and unavoidable, because for the foreseeable future robots will share floors with people. If an operator walks towards a robot, are they coming to assist it, moving past it to another station, or distracted mid-task? Simulating human randomness is currently a major frontier in physical AI and it's precisely what makes collaborative deployment (rather than caged-off cells) so hard.
And then contextual logic: knowing that a tool on the workbench is a tool, but the same tool on the floor is a hazard. Simulators often lack this common-sense layer entirely.
The Distributional Gap (the long tail)
‘It doesn't know what it doesn't know.’
You can simulate 99% of a robot's shift easily. The last mile is the 1% of events that happen rarely but are catastrophic for example a pallet breaking mid-lift, a power outage, a forklift cutting across the robot's path.
This shows up as out-of-distribution (OOD) failure. If a robot is trained on data from one production configuration and the line gets rebalanced with new fixtures, new part variants or a seasonal SKU changeover - the robot's confidence doesn't drop, it just makes a confident mistake which is arguably worse. And this is the norm as real factories are living systems that change weekly.
There's also what we would call the "data chimney" problem as we tend to simulate what is easy to simulate, not what is important to learn. This creates a bias where the robot is over-trained on simple tasks and completely blind to rare, complex failures which are usually the ones that halt a line.
Some questions we keep coming back to:
Where is the sharpest delta right now between what robots can do in demos vs. actual deployment?
Is the core problem generating better simulation or knowing which real-world scenarios to prioritise simulating in the first place?
How do you train your robots when you don't know what you don't know?
And how do you build the company itself to tighten that loop of learning from the real customer shop floor?
So what does this mean for where we look?
Each of these gaps points to a different kind of solutions and opportunities.
The perceptual and physical gaps are increasingly being attacked at the model and infrastructure level: better world models, higher-fidelity physics engines, tactile sensing, sim-to-real tooling. This maps to the intelligence and autonomy layer we flagged in our last piece as the highest-leverage part of the stack and the last mile is exactly why. Whoever meaningfully narrows these two gaps doesn't just improve one robot, they improve every robot built on top.
The semantic and distributional gaps, on the other hand can't be solved in a lab as these missing data lives on the customer's shop floor. This is why we believe verticalised, full-stack applications have a structural advantage over general-purpose plays: a company deployed inside a specific environment (electronics assembly, warehousing, lab automation) is continuously harvesting exactly the edge cases that a general-purpose humanoid company has to guess at. The narrower the wedge, the tighter the loop between failure in the field and improvement in the model.
In practice, the thing we pay closest attention to is not the demo, it's the learning loop. When we meet founders in this space, the questions we find ourselves coming back to are: how do you capture what happens in deployment, how quickly does it flow back into training, and does that loop get stronger as you scale? Impressive demos matter but the companies best placed for the long run are the ones where every hour in the field makes the product better.
The demos will keep getting more impressive. But the last mile isn't crossed once, it's crossed continuously in the unglamorous work of turning field failures into better models.
If you're building or investing in this space, please reach out, I would love to chat!